Fin mai 2024, le Google Leak a secoué la sphère SEO mondiale. Cette fuite inédite et massive de données (plus de 2 596 documents à décortiquer 😅) a mis en lumière de nombreuses informations sur les algorithmes et critères de classement de Google.
La firme américaine, après quelques jours, a finalement reconnu cette fuite. Nous pensons, à Ikova, qu’il est fondamental de prendre ces informations avec des pincettes. Il ne faut surtout pas tirer de conclusions hâtives sur les stratégies de Google. Imaginez que vous recevez une recette avec une liste d’ingrédients. Cependant, vous ne savez pas :
- Les quantités utilisées de chaque ingrédient (pondération quand tu nous tiens),
- Si tous les ingrédients sont utilisés,
- Et les différentes étapes pour réussir cette recette.
On est ici dans la même situation. Il faudra donc beaucoup de temps pour digérer ces informations et dans le même temps Google continuera d’actualiser ses algorithmes… Le SEO permet de garder la forme 🏋️ !
NavBoost : « Le » sujet saillant de ce Leak !
Certaines informations récemment divulguées via cette fuite d’infos révèlent néanmoins des aspects cruciaux des algorithmes de Google, confirmant des données partagées il y a quelques mois et soulignant leur importance pour les stratégies SEO.
Dans cet article, nous avons choisi de nous concentrer sur NavBoost, car nous considérons que c’est un des sujets saillants de ce leak, peut-être même le sujet n°1 à retenir.
En une phrase, NavBoost, c’est un système de classement ou plutôt d’ajustement des SERPs qui analyse les interactions utilisateurs et qui, de manière itérative, façonne les pages de résultats, au fur et à mesure qu’il récolte ces interactions.
Envie d’en savoir plus ? Alors, rentrons désormais dans le vif du sujet.
NavBoost : toute une histoire !
Confirmation récente de son existence
De nombreux professionnels du SEO suspectaient depuis des années que Google collectait et utilisait les données de clics comme facteurs de classement. C’est d’ailleurs un sujet qui a largement fait débat jusqu’à que NavBoost soit dévoilé.
Le terme « NavBoost » fait officiellement son apparition lors du procès antitrust intenté par les États-Unis à Google à la fin de l’année 2023. Plusieurs employés, dont le vice-président de Google Search Pandu Nayak, ont été appelés à témoigner lors de ce procès. Ils ont alors confirmé que la firme américaine s’appuyait sur l’analyse du comportement des utilisateurs, et tout particulièrement les clics effectués sur les résultats de recherche et les pages des sites web.
La collecte de données ? Une histoire ancienne pour Google
Finalement, cette collecte de données n’est pas si étonnante. Les premières collectes effectuées par Google remontent en effet au début de l’année 2000, avec l’introduction de la Google Toolbar qui embarquait à l’époque le fameux PageRank. Les plus expérimentés d’entre nous (pour ne pas dire les plus dinosaures d’entre nous) se souviendront avec émotion de cette toolbar qui a permis à Google de collecter des données essentielles sur les habitudes de navigation des internautes.
Depuis, Google a vu plus grand qu’une simple toolbar et a lancé en 2008 son navigateur, Google Chrome. Le lancement de Chrome visait à proposer un navigateur rapide et sécurisé, mais c’était également une manne d’informations sans précédent sur les données de clics et de parcours. Google aurait eu tort de ne pas les utiliser.
NavBoost révèle que Chrome n’est pas seulement un navigateur, mais un outil clé pour décrypter les comportements de navigation des utilisateurs. Les données qu’il fournit sont indispensables à Google pour améliorer ses algorithmes de recherche.
NavBoost qu’est-ce que c’est ?
Définition de NavBoost
NavBoost est (ou semble être si nous prenons un peu de précaution) un algorithme puissant de Google, dont l’objectif est d’améliorer la qualité des résultats de recherche en exploitant les données comportementales des utilisateurs.
En collectant et en analysant des données comportementales, des données de clics et de navigation, NavBoost permet de mieux comprendre l’intention des utilisateurs et d’optimiser le classement des pages web en conséquence. Pour les professionnels du SEO, il est essentiel de maîtriser ces mécanismes pour optimiser efficacement les sites web selon les critères utilisés par NavBoost.
NavBoost = Glue ?
Si vous creusez le sujet NavBoost, vous serez parfois confrontés au nom « Glue ». Alors, quelle différence entre NavBoost et Glue ? Eh bien, il n’y en aurait pas, ou pratiquement pas. C’est en tout cas ce que nous précise Nayak : « Glue n’est qu’un autre nom pour un NavBoost qui se concentre sur toutes les autres features d’une page (réponses directes, vidéos, images…) ».
NavBoost est spécialisé dans le classement des résultats web, tandis que Glue étend cette optimisation aux autres types de contenu sur les pages de résultats, comme les annonces, les vidéos et les images. Ainsi, ils contribuent ensemble à améliorer et à personnaliser l’expérience de recherche des utilisateurs sur Google.
Le professeur Edward Fox, témoin expert lors du procès antitrust, précise :
« Glue regroupe divers types d’interactions utilisateur (telles que les clics, les survols, les défilements et les balayages) et crée une métrique commune pour comparer les résultats Web et les fonctionnalités de recherche. Ce processus détermine à la fois si une fonctionnalité de recherche est déclenchée et où elle est déclenchée sur la page. »

NavBoost : comment ça marche ?
NavBoost est l’un des outils avancés de Google, conçu pour affiner les résultats de son moteur grâce à une analyse comportementale approfondie. C’est un outil complexe de reclassement des SERPs. Voici les étapes principales de ce processus :
1. Collecte des données avec Chrome
Google utilise les informations provenant de son navigateur Chrome pour recueillir des données sur les interactions des utilisateurs. Cela inclut les clics, les temps de visite, les interactions avec les pages et d’autres signaux d’engagement.
2. Analyse avec les modules
Plusieurs modules analytiques interviennent à cette étape pour évaluer la qualité du contenu en fonction de l’engagement des utilisateurs. Ces modules scrutent les données collectées afin d’identifier les tendances et les préférences des utilisateurs, permettant ainsi de mesurer la pertinence des contenus proposés. Les interactions des utilisateurs, comme les clics « longs » et le temps passé sur une page, servent d’indicateurs clés dans cette analyse.
3. Réinjection dans les modèles de Deep Learning
Les données analysées sont réinjectées dans les modèles de deep learning de Google. Ces modèles sont utilisés pour ajuster et affiner les algorithmes de classement en fonction des nouvelles informations obtenues. À cette étape, il est important de noter que probablement seules les pages bénéficiant d’un volume d’engagements suffisamment élevé sont susceptibles de bénéficier ou de subir les conséquences de Navboost.
4. Ajustement du classement dans les SERP
Basé sur l’analyse approfondie des données collectées par NavBoost, ainsi que sur les résultats provenant d’autres algorithmes et modèles de deep learning, Google ajuste le classement des pages dans les SERP. Ce processus peut inclure la promotion ou la rétrogradation de pages spécifiques, en fonction de leur performance par rapport aux critères d’engagement des utilisateurs.
Le processus est itératif, ce qui permet aux pages de résultats de recherche (SERPs) de s’ajuster continuellement aux préférences des utilisateurs exprimées à travers leurs interactions.
Les modules utilisés par NavBoost et leur impact sur le SEO
Voici quelques exemples des modules utilisés par NavBoost (modules qui sont cités dans le Leak).
A noter : CRAPS signifierait « Click and Results Prediction System ».
1. Module « Quality Navboost Craps Craps Click Signals«
Ce module est particulièrement important, car il permettrait de qualifier les clics. Voici l’ensemble des métriques composant ce module :

Ces métriques aident à comprendre diverses dimensions des interactions des utilisateurs et leurs implications pour le classement dans Google.
On peut distinguer, entre autres, les bons et les mauvais clics (« goodClicks » & « badClicks »). Ces métriques de « Clicks » distingueraient a priori les clics bénéfiques de ceux qui sont moins pertinents, influençant positivement ou négativement le classement des pages.
L’information principale à retenir serait la corrélation effectuée entre le clic et le temps passé sur une page (« unsquashedLastLongestClicks »). Plus un utilisateur passerait de temps sur une page après avoir cliqué, plus le clic serait valorisé, ce qui réaffirmerait la qualité et la pertinence du contenu cliqué (idée qui n’est pas sans nous remémorer le concept de pogo-sticking).
Attention : Nous ne pouvons qu’interpréter certaines métriques, car aucune grille de lecture n’existe à ce jour, certains termes restant très obscurs.
Il est tout particulièrement intéressant de mettre ces métriques en relation avec l’article publié par le Search Engine Journal intitulé «7 must-see Google Search ranking documents in antitrust trial exhibits» (7 documents de classement de recherche Google à voir absolument dans les pièces à conviction du procès antitrust) publié le 3 novembre 2023.
Document issu du procès anti-trust
Ce document illustre les défis auxquels même les équipes de Google sont confrontées lorsqu’il s’agit de qualifier les clics et de juger de leur qualité. L’article met en lumière le fait qu’un enregistrement de clic n’est intrinsèquement ni bon ni mauvais. Tout l’enjeu réside dans la capacité à interpréter le comportement de l’utilisateur et à le convertir en un jugement de valeur.
2. Module « Quality Navboost Craps Craps Device »
Ce module pourrait identifier le type d’appareil et de navigateur utilisé par un utilisateur lors d’une requête de recherche. Cette identification permettrait de personnaliser les résultats de recherche en fonction des caractéristiques techniques de l’appareil et du navigateur. En théorie, ce module influencerait les résultats de recherche de plusieurs manières :
- Optimisation pour les appareils mobiles et tablettes : Les sites web optimisés pour ces appareils pourraient être mieux classés dans les résultats de recherche lorsqu’une requête est effectuée depuis un tel dispositif.
- Filtrage par compatibilité : Les sites qui ne sont pas compatibles avec les anciens navigateurs ou appareils pourraient être exclus des résultats de recherche.
- Adaptation aux capacités techniques : Les résultats pourraient varier en fonction des spécificités de l’appareil et du navigateur utilisé par l’internaute.
3. Module « Quality Navboost Craps Feature Craps Data »
Ce module serait conçu pour collecter et analyser les données comportementales des utilisateurs, en mettant une importance particulière sur la localisation. Cela permettrait une personnalisation et une pertinence accrues des résultats de recherche selon des critères spécifiques tels que le pays, la langue, et surtout la localisation géographique précise. Voici un aperçu des attributs clés du module :
- Pays (
country) : Ce paramètre identifierait le pays de l’utilisateur, comme « US », permettant une agrégation des données soit à un niveau national soit global si non spécifié. - Langue (
language) : La langue de l’utilisateur, telle que « EN », serait prise en compte, avec une possibilité d’agrégation sur toutes les langues si non spécifiée. - Identifiant de localisation (
locationId) : Ce paramètre serait clé car il permettrait d’analyser les données à un niveau très granulaire, tel que les zones métropolitaines ou les villes. - Signaux (
signals) : Ces signaux, spécifiques à chaque localité, enrichiraient l’analyse des comportements des utilisateurs en fonction de leur emplacement géographique.
En mettant l’accent sur la localisation, ce module pourrait ajuster de manière significative le classement des sites Web dans les résultats de recherche. Les sites qui répondraient bien aux critères locaux d’engagement des utilisateurs pourraient être favorisés avec un classement plus élevé, tandis que les autres pourraient être rétrogradés.
4. Module « Image Quality Navboost Image Quality Click Signals »
Ce module évaluerait la qualité des images en fonction des interactions des utilisateurs, telles que les clics sur les images, le temps passé à les visualiser, et l’engagement avec le contenu visuel. Les images jugées attractives et engageantes seraient favorisées, ce qui pourrait améliorer le classement des pages contenant ces images. On peut imaginer que Glue, tel que nous l’avons défini précédemment, joue un rôle dans ce module.
5. Module « Research Science Search Navboost QueryInfo »
Ce module serait conçu pour capturer et analyser des données spécifiques liées à des requêtes de recherche. Google organiserait les infos associées à chaque requête en « tuple ».
Un tuple, en termes simples, serait une collection d’éléments qui, dans ce module, correspondrait à un enregistrement des interactions utilisateurs pour une requête donnée. Cette structure permettrait d’analyser finement le comportement des utilisateurs face aux résultats de recherche.
Le nom du module suggère que ce module pourrait servir à analyser les tendances de recherche, les habitudes des utilisateurs, et l’interaction avec les résultats de recherche dans un contexte plus académique ou scientifique.
Exemple d’utilisation des données collectées par NavBoost
Le cas des SiteLinks
Les liens sitelink sont générés par Google en utilisant les données fournies par NavBoost. Ces liens s’affichent sous le résultat principal de recherche pour proposer des informations pertinentes spécifiques au site. Google tend à favoriser, pour ces sitelinks, les liens qui attirent davantage de visites et d’interactions de la part des utilisateurs. En somme, ces liens sont déterminés par des signaux comportementaux, qui constituent l’essence même de NavBoost.

Un rôle bien plus large que les SiteLinks
Les liens sitelinks ne sont très probablement que la partie émergée de l’iceberg NavBoost. Ce système jouerait un rôle bien plus central dans l’ago, en modelant de manière itérative les pages de résultats de recherche à l’aide des données d’usage répétées des internautes, impactant significativement les requêtes à forte volumétrie.
L’utilisation de ces données comportementales et le caractère itératif de NavBoost est d’ailleurs clairement illustrés dans les documents révélés lors du procès antitrust.
Petit rappel du fonctionnement d’une recherche dans Google
Fin 2023, lors du procès antitrust, des documents internes de Google ont été révélés. Ils expliquaient, sans le nommer, l’existence de NavBoost dans l’algorithme.
Les documents issus du procès AntiTrust
En quelques slides (repris ci-dessous), ces documents ont dévoilé les mécanismes qui se cachent derrière la recherche Google. Nous y apprenons pourquoi les résultats de Google ne sont pas issus d’un processus « magique » (ah bon !), mais sont plutôt le fruit d’un dialogue constant entre l’utilisateur et l’algorithme. Plongez avec nous dans les coulisses de ce processus fascinant. Rien que ça !
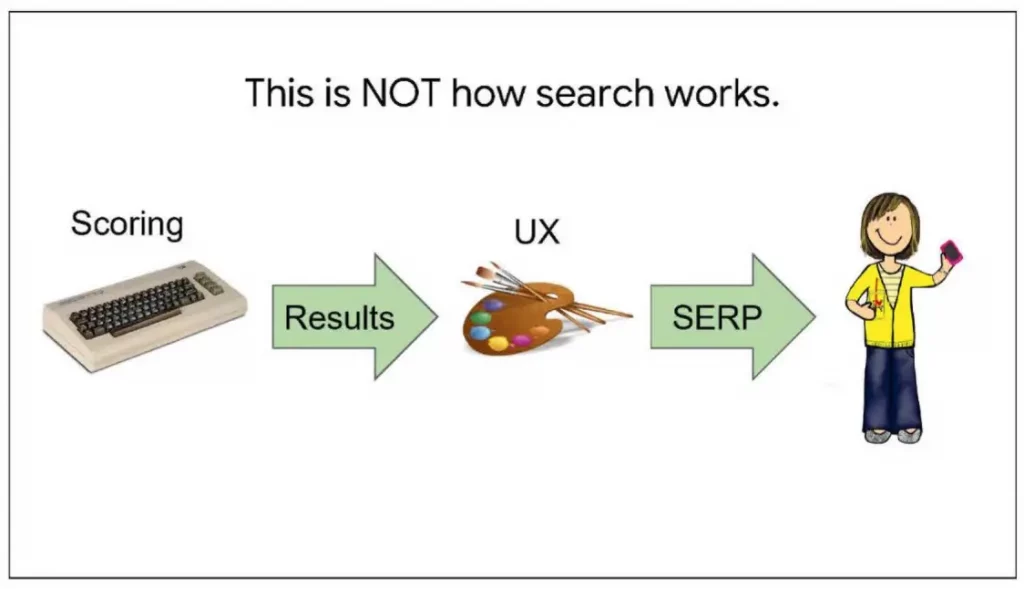
La recherche ne fonctionne pas simplement en appliquant des scores et une UX (expérience utilisateur) aux résultats pour les afficher sur une SERP (page de résultats de recherche). Cette approche est incomplète et ne produit pas de résultats de qualité.
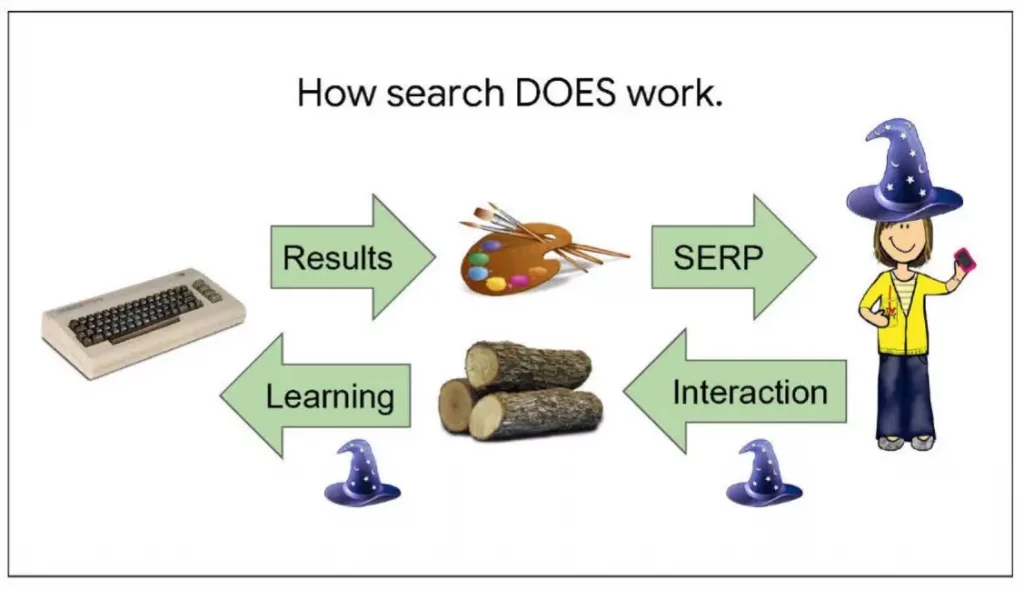
La recherche repose sur un dialogue bidirectionnel. Les interactions des utilisateurs (clics, temps passé sur une page) enseignent à Google quelles sont les informations (= les pages) pertinentes. Ces actions sont enregistrées et analysées pour améliorer continuellement les résultats de recherche. (Pour ceux qui s’interrogent sur le pourquoi des « bûches » : les rondins de bois sont souvent appelés « logs » en anglais, un terme qui désigne à la fois les bûches mais aussi les registres de données ou les journaux d’événements informatiques.)
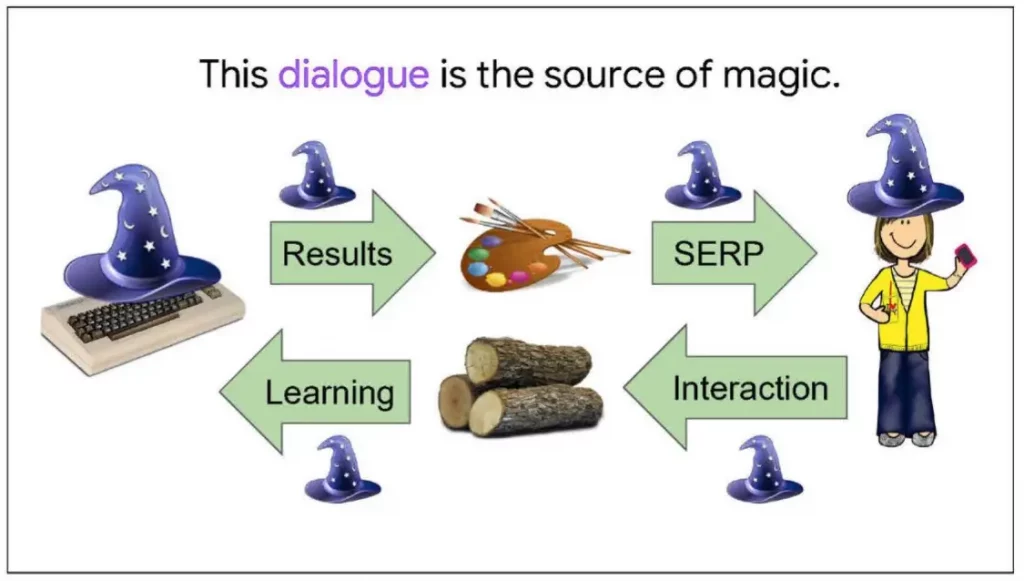
La magie de Google réside dans ce dialogue constant avec les utilisateurs. Chaque interaction, chaque requête, et chaque retour d’information contribuent à rendre le moteur de recherche plus intelligent et plus efficace.
NavBoost et Instant Glue
NavBoost joue un rôle prépondérant en utilisant les données des clics des utilisateurs pour ajuster et améliorer la pertinence des résultats de recherche. Le système Navboost est entraîné sur les données des utilisateurs. Il mémoriserait tous les clics effectués sur les requêtes des 13 derniers mois.
Il y aurait même un « instant NavBoost/Glue » qui se concentrerait uniquement sur les données des dernières 24 heures avec une latence d’environ 10 minutes. Ce système semble être une version plus dynamique et réactive de NavBoost/Glue, permettant des ajustements rapides et des mises à jour fréquentes des résultats de recherche basés sur les interactions les plus récentes des utilisateurs. Cela ressemble au fameux QDF = « Query Deserves Freshness » !

Slide issu des documents du Professor Douglas W. Oard
Cette optimisation dynamique garantit que les résultats répondent mieux aux attentes des utilisateurs, en tenant compte de leurs comportements et préférences, rendant ainsi Google plus performant et intuitif.
NavBoost, la confirmation de Google
Suite au procès antitrust, Google a confirmé par l’intermédiaire de son compte X Google Search Liaison et de Danny Sullivan, l’utilisation de signaux comportementaux dans son algorithme.
Bien qu’il soit prudent de ne pas prendre toutes les informations divulguées lors du leak au pied de la lettre (raison pour laquelle nous avons utilisé le conditionnel dans notre discussion sur les « modules »), ces confirmations renforcent l’idée que NavBoost joue un rôle central dans l’algorithme de Google.
Ci-dessous, 2 tweets de la SearchLiaison qui confirment l’utilisation des données d’interaction tout en relativisant leur impact. Si les signaux comportementaux sont significatifs, ils sont seulement une partie d’un ensemble complexe de facteurs que Google considère pour optimiser l’expérience de recherche.
It was along the lines of of course we use user interaction signals, and it says this on the How Search Works site, plus it says this in your 2019 article when you asked us. Which leads to not the "do you use them" but "how do you use them" which I said we won't go into the…
— Google SearchLiaison (@searchliaison) November 13, 2023
If you think further about this type of belief, no one would ever rank in the first place if that were supposedly all that matters — because how would a new site (including your site, which would have been new at one point) ever been seen? The reality is we use a variety of…
— Google SearchLiaison (@searchliaison) June 10, 2024
Checklist pour optimiser votre site pour NavBoost
Toujours là ? Super et bravo ! Comment tirer le meilleur parti de NavBoost ? À la lumière des informations recueillies, voici quelques points clés sur lesquels vous devriez vraiment vous concentrer afin d’optimiser votre site pour NavBoost :
1. Contenu de haute qualité : Fournissez un contenu engageant et informatif qui répond aux besoins de votre audience. Cela aide à maintenir les utilisateurs sur votre site plus longtemps, réduisant ainsi les taux de rebond et améliorant le temps de visite. Ce type de contenu favorise les « clics longs », ce qui semble être valorisé par NavBoost. Un taux élevé de clics longs signale à l’algorithme que votre contenu est pertinent et utile, influençant positivement votre classement dans les résultats de recherche.
2. Navigation claire : Assurez-vous que votre site web a une structure logique et intuitive, ce qui peut améliorer votre classement Google. Nos recommandations :
- utilisez des libellés de menu clairs
- utilisez une navigation par fil d’Ariane
- utilisez des liens internes pour guider efficacement les utilisateurs à travers votre contenu.
3. Expérience utilisateur : Créez une interface conviviale avec une mise en page propre, des popups minimaux et un texte lisible. Assurez-vous que tous les éléments interactifs soient faciles à utiliser et accessibles.
4. Vitesse du site : Des temps de chargement rapides sont essentiels pour la satisfaction des utilisateurs et le classement dans les moteurs de recherche.
Nos recommandations : optimisez le temps de chargement de votre site web en compressant les images, en réduisant les requêtes HTTP et en activant la mise en cache du navigateur.
5. Optimisation mobile : Assurez-vous que votre site web est responsive et performant sur les appareils mobiles. Cela inclut l’utilisation de tailles de police appropriées, d’éléments cliquables et des temps de chargement rapides.
6. Observation des SERPs : Analysez attentivement les résultats qui apparaissent sur les pages de résultats de recherche. Déterminez les questions auxquelles ces résultats répondent, les intentions qu’ils visent à satisfaire, et les attributs qu’ils intègrent, tant sur le fond (texte, images, vidéos) que sur la forme (comparatifs, articles de fond, pages produit).
Cette analyse vous guidera dans la création de contenus adaptés. Sur cette base, plutôt que de simplement copier ce qui existe déjà, aspirez à vous distinguer tout en répondant efficacement à l’intention de l’utilisateur. Rince and repeat!
Vous êtes arrivé.e.s à la fin. 💪 Merci !
Sources :
- How Google Search and ranking works, according to Google’s Pandu Nayak, Search Engine Journal, 5 décembre 2023.
- 7 must-see Google Search ranking documents in antitrust trial exhibits, Search Engine Journal, 3 novembre 2023.
- Présentation du professeur Douglas Oard Trial Exhibit-UPXD105: U.S.v. Plaintiff States v. Google LLC.
- NavBoost décrypté : comment les clics utilisateurs influencent le classement Google, Abondance, 29 mai 2024.
- 2596.org, Google Search Algorithm Leak par Matt Hodson
- An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them, SparkToro, 27 mai 2024.
- Ranking factors (SEMrush study), le 4 janvier 2024